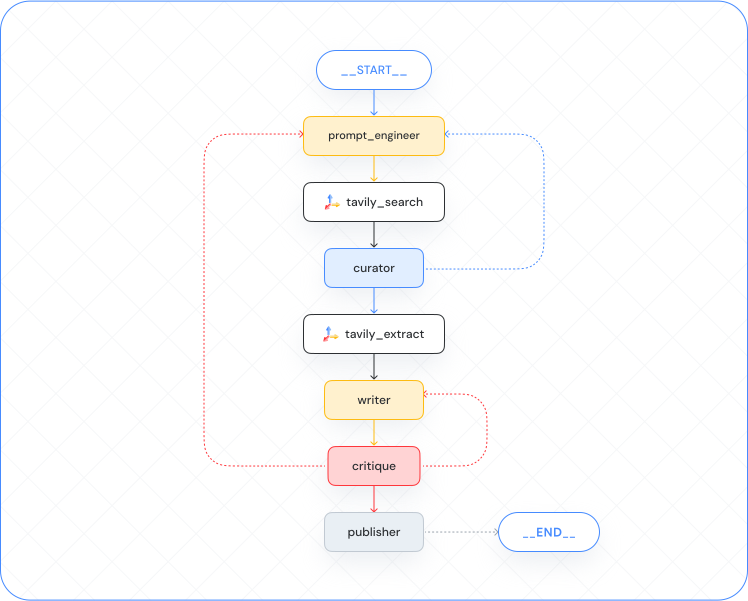
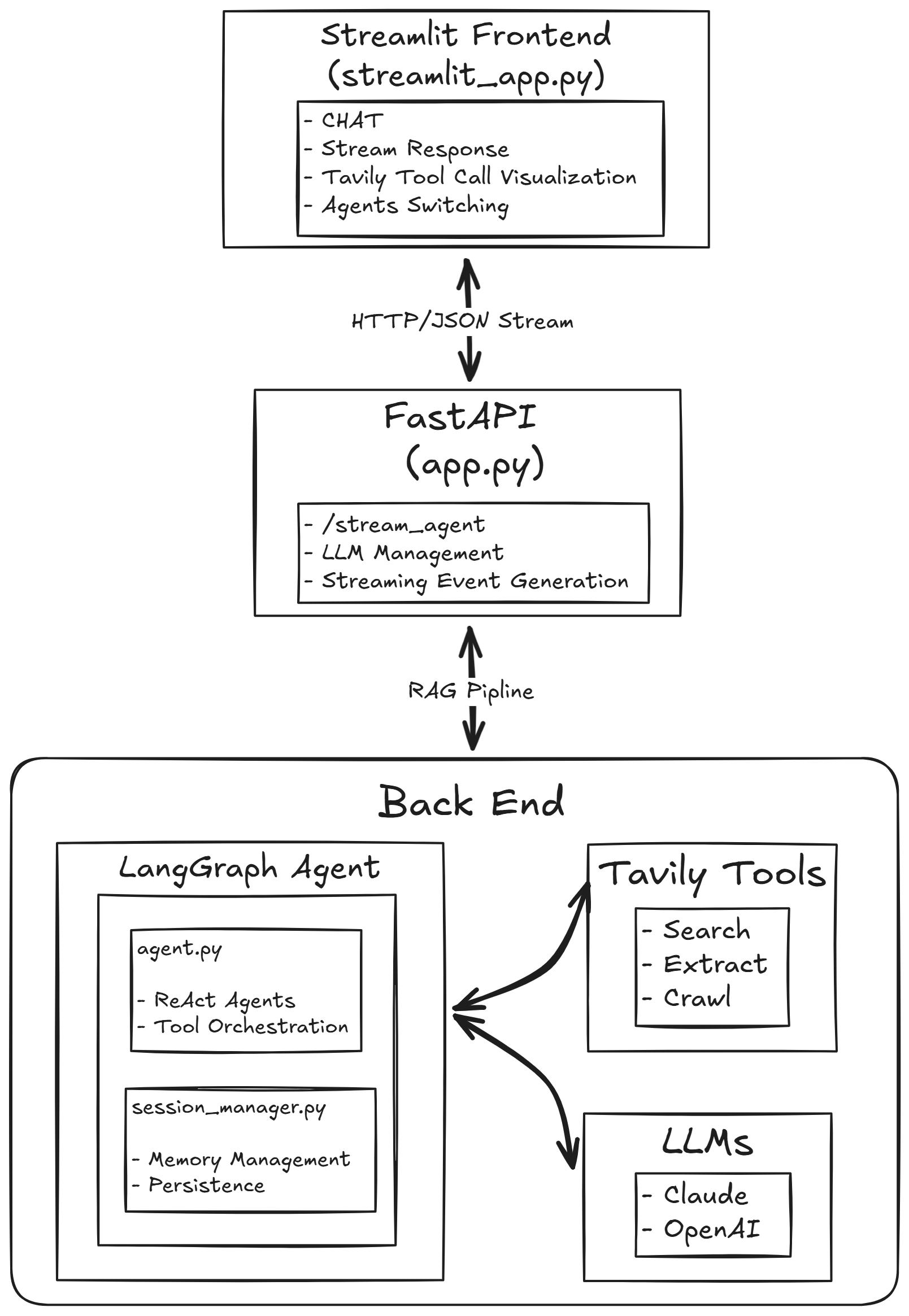
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
| import logging
from typing import Callable, Any
from langchain_core.language_models import BaseChatModel
from langchain_tavily import TavilyCrawl, TavilyExtract, TavilySearch
from langgraph.checkpoint.memory import MemorySaver
from langgraph.prebuilt import create_react_agent
import json
import ast
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
def create_output_summarizer(summary_llm: BaseChatModel) -> Callable[[str, str], dict]:
"""
创建输出摘要器
Args:
summary_llm: 用于生成摘要的语言模型
Returns:
摘要函数
"""
def summarize_output(tool_output: str, user_message: str = "") -> dict:
"""
对工具输出进行摘要处理
Args:
tool_output: 工具原始输出
user_message: 用户消息(用于上下文)
Returns:
包含摘要、URL 和 favicon 的字典
"""
if not tool_output or tool_output.strip() == "":
return {"summary": tool_output, "urls": []}
try:
parsed_output = json.loads(tool_output)
except (json.JSONDecodeError, TypeError):
try:
parsed_output = ast.literal_eval(tool_output)
except (ValueError, SyntaxError):
return {"summary": tool_output, "urls": []}
urls = []
favicons = []
content = ""
if isinstance(parsed_output, dict) and 'results' in parsed_output:
items = parsed_output['results']
elif isinstance(parsed_output, list):
items = parsed_output
else:
return {"summary": tool_output, "urls": [], "favicons": []}
for item in items:
if isinstance(item, dict):
if 'url' in item:
urls.append(item['url'])
if 'favicon' in item:
favicons.append(item['favicon'])
if 'raw_content' in item:
content += item['raw_content'] + "\n\n"
if content:
summary_prompt = f"""请将以下内容总结为相关格式,以帮助回答用户的问题。
重点关注对回答以下问题最有用的关键信息:{user_message}
删除冗余信息并突出最重要的发现。
内容:
{content[:3000]} # 限制内容长度
请提供一个清晰、有组织的摘要,捕捉与用户问题相关的基本信息:
"""
try:
summary = summary_llm.invoke(summary_prompt).content
except Exception as e:
logger.error(f"摘要生成失败: {e}")
summary = content[:500]
else:
summary = tool_output
return {"summary": summary, "urls": urls, "favicons": favicons}
return summarize_output
class WebAgent:
"""
Web智能体 类,集成 Tavily 搜索、提取和爬取功能
"""
def __init__(self, checkpointer: MemorySaver = None):
"""
初始化 Web 智能体
Args:
checkpointer: LangGraph 检查点存储器(用于对话记忆)
"""
self.checkpointer = checkpointer
def build_graph(
self,
api_key: str,
llm: BaseChatModel,
prompt: str,
summary_llm: BaseChatModel,
user_message: str = "",
mode: str = "fast",
topic: str = "general",
time_range: str = None
):
"""
构建并编译 LangGraph 工作流
Args:
api_key: Tavily API 密钥
llm: 主要语言模型(用于智能体推理)
prompt: 系统提示词
summary_llm: 用于摘要的语言模型
user_message: 用户原始消息(用于摘要上下文)
mode: 搜索模式,"fast"(快速模式)或 "deep"(深度思考模式),默认为 "fast"
topic: 搜索主题,"general"(通用)、"news"(新闻)或 "finance"(财经),默认为 "general"
time_range: 时间范围过滤,可选 "day"、"week"、"month"、"year",默认不限制
Returns:
编译后的 LangGraph 智能体
"""
if not api_key:
raise ValueError("错误:未提供 Tavily API 密钥")
depth = "basic" if mode == "fast" else "advanced"
max_results = 3 if mode == "fast" else 5
include_images = False if mode == "fast" else True
crawl_limit = 5 if mode == "fast" else 15
search_params = {
"max_results": max_results,
"tavily_api_key": api_key,
"include_favicon": True,
"search_depth": depth,
"include_answer": False,
"topic": topic,
"include_images": include_images,
}
if time_range:
search_params["time_range"] = time_range
search = TavilySearch(**search_params)
extract = TavilyExtract(
extract_depth=depth,
tavily_api_key=api_key,
include_favicon=True,
include_images=include_images,
)
crawl = TavilyCrawl(
tavily_api_key=api_key,
include_favicon=True,
limit=crawl_limit
)
output_summarizer = create_output_summarizer(summary_llm)
class SummarizingTavilyExtract(TavilyExtract):
def _run(self, *args, **kwargs):
kwargs.pop('run_manager', None)
result = super()._run(*args, **kwargs)
return output_summarizer(str(result), user_message)
async def _arun(self, *args, **kwargs):
kwargs.pop('run_manager', None)
result = await super()._arun(*args, **kwargs)
return output_summarizer(str(result), user_message)
class SummarizingTavilyCrawl(TavilyCrawl):
def _run(self, *args, **kwargs):
kwargs.pop('run_manager', None)
result = super()._run(*args, **kwargs)
return output_summarizer(str(result), user_message)
async def _arun(self, *args, **kwargs):
kwargs.pop('run_manager', None)
result = await super()._arun(*args, **kwargs)
return output_summarizer(str(result), user_message)
extract_with_summary = SummarizingTavilyExtract(
extract_depth=extract.extract_depth,
tavily_api_key=api_key,
include_favicon=extract.include_favicon,
description=extract.description
)
crawl_with_summary = SummarizingTavilyCrawl(
tavily_api_key=api_key,
include_favicon=crawl.include_favicon,
limit=crawl.limit,
description=crawl.description
)
return create_react_agent(
prompt=prompt,
model=llm,
tools=[search, extract_with_summary, crawl_with_summary],
checkpointer=self.checkpointer,
)
|